Czy nie byłoby pięknie gdyby każda zmiana wprowadzona w repozytorium automatycznie pojawiała się w środowisku produkcyjnym. Z tym zagadnieniem web developerzy borykają się już przez długie lata.
Na rynku istnieje wiele platform, usług i rozwiązań, które są w stanie zaspokoić te potrzeby w różnym zakresie. Automatyzacja to bardzo złożony temat i może przybierać różne formy oraz zakres. Wszystko zależy od tego w jaki sposób dostarczamy naszą aplikację internetową klientom końcowym. W przypadku gdy mamy do czynienia z rozbudowanym systemem, na który składają się różne środowiska uruchomieniowe(dev, test, prod etc), proces automatyzacji będzie wyglądał zgoła inaczej niż jeżeli w przypadku prostej strony internetowej opartej o worpdress.
Możemy sobie wyobrazić system, który jest cały czas rozwijany i zmiany powinny w sposób płynny być dostarczane na odpowiednie środowisko. Dodatkowo każdorazowo przed osadzeniem zmian z repozytorium powinniśmy zadbać o wykonanie testów. Moglibyśmy do tego dodać jeszcze jeden element jakim byłaby konieczność wygenerowania obrazu dockera na podstawie źródeł znajdujących się repozytorium git. Podmiana obrazu który byłby bazą dla kontenerów uruchomionych np. w kubernetisie byłaby ostatnim krokiem tej układanki.
Jak widzisz proces ten może być bardzo skomplikowany i łatwo byłoby o czymś zapomnień albo wykonać coś nieprawidłowo w trakcje ręcznego wykonywania po kolei tych operacji. Dlatego właśnie dąży się do tego aby tak złożone operacje były wykonywane automatycznie. To pozwala na skrócenie czasu dostarczania zmian oraz ograniczenie błędów i usterek.
W tym artykule nie będziemy budować konfiguracji pod tak złożony proces jak ten opisany powyżej. Skupimy się na podstawach, które pozwolą nam zadbać o automatyzacje w mniejszej skali.
Aplikacja internetowa, dla której będziemy budować środowisko
Na początku musimy sobie postawić cel, zatem powinniśmy zastanowić się co i jak chcemy zautomatyzować. Za nasz przykład posłuży nam strona internetowa na bazie wordpress. Punktem wyjścia będzie system kontroli wersji jakim jest git. Bez tego elementu nie możemy zacząć, gdyż w zasadzie wszystkie współcześnie występujące modele tworzenia oprogramowania są oparte o git lub też inny system kontroli wersji.
W tym artykule będziemy starali zbudować się konfigurację na bazie Bitbucket Pipelines. Jednakże podobne rozwiązania istnieją u konkurencyjnych dostawców(Github actions, gitlab itd).
Witryna którą budujemy i rozwijamy jest osadzona na serwerze w ramach klasycznego modelu LAMP. Aktualizacje będziemy publikować przy pomocy git poprzez pobieranie najnowszych zmian. Aby nasz przykład nie był zbyt prosty proponuję abyśmy działali w ramach dwóch gałęzi: master oraz dev. Będziemy dysponować dwoma środowiskami uruchomieniowymi. Pierwszym będzie serwis w wersji developerskiej. Tam będą rozwijane nowe funkcje, wprowadzane modyfikacje itp. Drugie środowisko będzie pełnić rolę produkcyjną. Tym samym schemat powiązań pomiędzy gałęziami git oraz środowiskami będzie wyglądał następująco:
- master -> produkcja
- dev -> development
Początek czyli git hooks
Zanim skupimy się na rozwiązaniach, które dostarcza nam bitbucket zatrzymajmy się na moment i zastanówmy się jak to wszystko jest możliwe. Git posiada w sobie wspaniałą funkcjonalność jaką są tzw. git hooks.
Jest to nic innego jak mechanizm pozwalający wpinać się z własnym kodem pod konkretne zdarzenia, które mają miejsce w repozytorium(przed commitem, po commicie itd). Na bazie tego rozwiązania wiele lat temu, budowano pierwsze mechanizmy automatyzujące. Dzisiaj nie jest inaczej, popularne platformy do wersjonowania kodu źródłowego również bazują na tym rozwiązaniu. Oczywiście teraz obudowano to w zaawansowane mechanizmy na różnym poziomie, jednak podstawą wyzwalającą kolejne działania jest właśnie git hook.
Bitbucket Pipelines
Załóżmy, że dysponujemy repozytorium utrzymywanym w ramach bitbucketa. Jeśli nie posiadamy jeszcze gałęzi dev, to powinniśmy o to zadbać(git checkout -b dev). Nadszedł moment aby wyjaśnić czym są te magiczne pipeliny. Otóż jest to nic innego jak ciąg instrukcji sformatowany w pliku yaml, wykonywany w określonych sytuacjach. Powinniśmy wiedzieć, że wszystko co się wykonuje w ramach pipeline jest zamknięte w kontener, budowany ze wskazanego obrazu dockera. Bitbucket Pipelines jest zintegrowane z dockerhubem, także możemy korzystać własnych obrazów.
Aby myśleć o automatyzacji musimy skonfigurować kilka elementów w ramach ustawień naszego repo. W pierwszej kolejności musimy włączyć pipelines w ramach naszego repozytorium. Domyślnie ta opcja jest wyłączona.
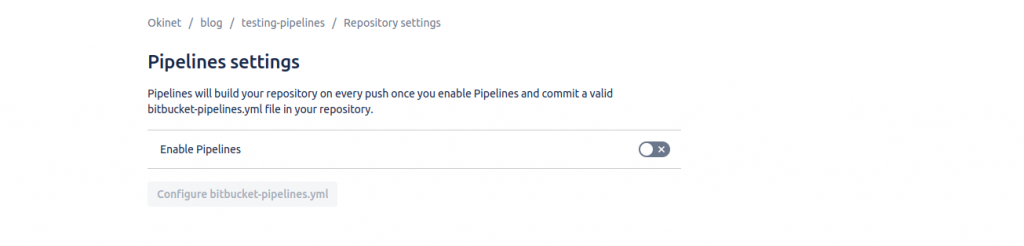
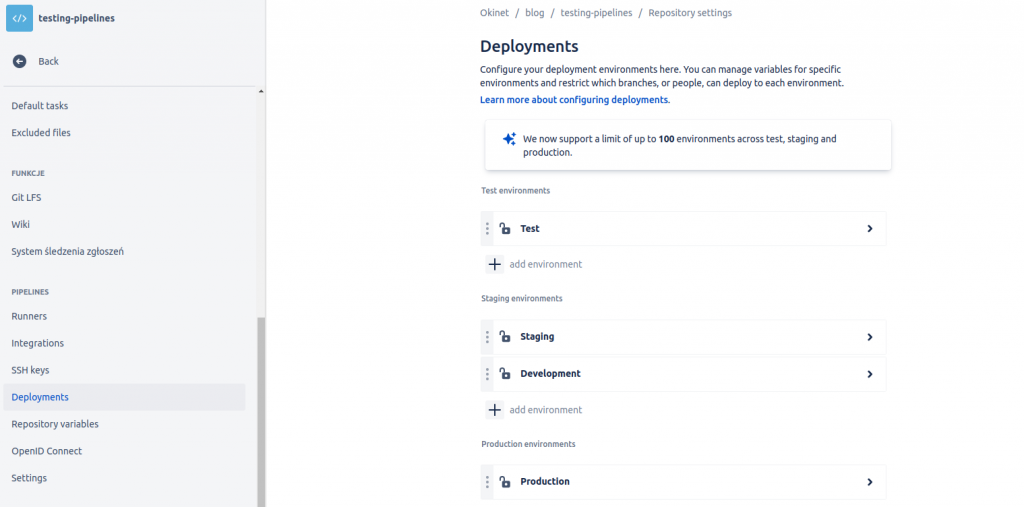
Kolejnym krokiem, który musimy wykonać to ustawienie odpowiednio środowisk uruchomieniowych. Należy w ustawieniach repozytorium przejść do zakładki pipelines->deployments. Tam pojawi się ekran, na którym będą widocznie domyślnie skonfigurowane środowiska(test,stage,prod). My w naszym uproszczonym modelu będziemy korzystać tylko z dwóch czyli dev oraz prod. Jak widzisz musimy zająć się dodaniem środowiska dev. Dla porządku dodajmy nowy element do sekcji staging.
Plik konfiguracyjny bitbucket-pipelines.yml
Sercem mechanizmu jest plik specjalnym plik, który musi być przechowywany w ramach repozytorium. Wraz z dodaniem pliku nasze instrukcje będą wykonywane przez mechanizmy bitbucketa. Zanim jednak to zrobimy przyjrzymy się składni oraz podstawowym elementom składowym.
Image
Elementem najwyższego rzędu, który będzie nam zawsze towarzyszył jest „image”. Jest to miejsce w którym powinniśmy podać nazwę obrazu dockera, który to stanie się podstawą do stworzenia kontenera. W ramach tego kontenera będą uruchomiane nasze instrukcje. Możemy przygotowywać swoje obrazy, które będą już w sobie posiadały zainstalowane i skonfigurowane oprogramowanie. Możemy też posłużyć się jakimś obrazem ogólnego zastosowania np. ubuntu
Definitions
Ten element nie jest zawsze wykorzystywany, gdyż w małych projektach instrukcje nie są zamykane w definicje. W ramach definicji stosuje podział na kroki. Te z kolei zawierają w sobie konkretne komendy do wykonania. Wykorzystywanie tej klauzuli pozwoli Ci zachować czytelność oraz sprawi, że niektóre kroki nie będą musiały być powielane.
Pipelines
Pod tym słowem kluczowym skonfigurowane są kolejne działania, które mają zostać wykonane. Sprowadza się do to ustalenia kolejno następujących po sobie kroków, które mogły być wcześniej opisane w sekcji definitions. Operacje mogą być wykonywane w podziale na gałęzie repozytorium git.
Clone
Bitbucket przed wykonaniem każdego kroku robit tzw git clone, czyli pobiera świeżą kopię repozytorium git w kontekście uruchamianej procedury. Ma to oczywiście swoje uzasadnienie, gdyż najczęściej przeprowadzane są testy w ramach kodu znajdującego się w repo. Nie zawsze jednak jest to nam potrzebne, czasami nawet może to przeszkadzać. Przykładem takiej sytuacji może być deploy, który próbuje uruchomić nową wersję aplikacji w oparciu o procesy w poprzedniej krokach. Właśnie dlatego klauzula clone, pozwala nam na poziomie konfiguracji pipelines sterować tym zachowaniem.
Przykład konfiguracji realizującej deployment strony internetowej
Poniżej znajduje się przykład kompletnego pliku bitbucket-pipelines.yml. Gdy załączymy go do głównego katalogu repozytorium mając jednocześnie uruchomioną opcję „pipelines” w konfiguracji, wtedy bitbucket wraz z każdym commitem rozpocznie uruchamianie procesu deploymentu.


